A survey of Flash Translation Layer (2021-02-08)
3.1.4 비교
FTL 성능 수준은 파일 시스템의 읽기/쓰기 성능과, 매핑 정보를 저장하기 위한 메모리 요구 사항에 따라 비교됨
FTL의 읽기/쓰기 성능은 I/O 범위이기 때문에, 플래시의 I/O 작업(read, write, erase) 수에 따라 측정한다.
읽기 및 쓰기 비용 계산 방법
(※ FTL의 매핑 테이블이 RAM 안에 유지되고, 매핑 테이블에 대한 접근 비용이 0이라고 가정한다.)
- Cread = xTr // 파일 시스템 계층에서 읽기 명령의 비용
- Cwrite = PiTw + Po(xTr + Tw) + Pe(Tc + Tw + Te) // 파일 시스템 계층에서 쓰기 명령의 비용
Tr - 플래시 메모리 계층에서 읽기
Tw - 플래시 메모리 계층에서 쓰기
Te - 플래시 메모리 계층에서 지우기
(※ 아래 설명)
Pi - 쓰기 명령이 내부 위치에서 수행될 확률
Po - 빈블록 스캔 후 쓰기 명령을 수행할 확률
Pe - 쓰기 작업 시 지우기 작업이 발생할 확률
Tc - 블록 내 유효한 데이터를 다른 free block에 복사
Te - 매핑 테이블 변경 후 원래 블록을 제거
- Cread에서 변수 x
섹터 및 블록 매핑에서는 1 (읽을 섹터를 매핑 테이블에서 직접 결정할 수 있기 때문)
하이브리드 매핑은 1 <= x <= n (n == 블록 내의 섹터 수)
-> 하이브리드 매핑은 예비 영역에 저장된 논리 섹터 번호를 스캔해야만 읽기가 가능함
-> 섹터 및 블록에 비해 하이브리드가 읽기 비용이 더 높음
- Cwrite 경우 3가지
1. 쓰기 작업을 직접적으로 하는 경우
pi - 쓰기 명령이 내부 위치에서 수행될 확률
2. 빈 블록 위치를 스캔후 작업을 수행하는 경우
추가적인 읽기 작업이 필요할 수 있음
쓰기 작업 시 지우기 작업이 필요할 수 있음
Po - 빈블록 스캔 후 쓰기 명령을 수행할 확률
3. 쓰기 작업 시 지우기 작업이 발생하는 경우
쓰기가 지우는 작업을 요청할 때 FTL 알고리즘 수행 과정(가정)
1) 삭제 할 블록 내 유효한 데이터는 다른 free block에 복사하고, 다시 새 블록으로 복사됨 (Tc)
2) 쓰기 작업이 수행 (Tw)
3) 매핑 테이블을 변경 후 4) 원래 블록을 제거 (Te)
Pe - 쓰기 작업 시 지우기 작업이 발생할 확률
Te, Tc가 Tr, Tw에 비해 고비용의 작업
-> 쓰기 비용을 계산할 때 Te가 핵심 포인트
섹터 매핑은 쓰기당 소거 작업이 발생할 확률이 상대적으로 낮으나, 블록 매핑은 상대적으로 높음
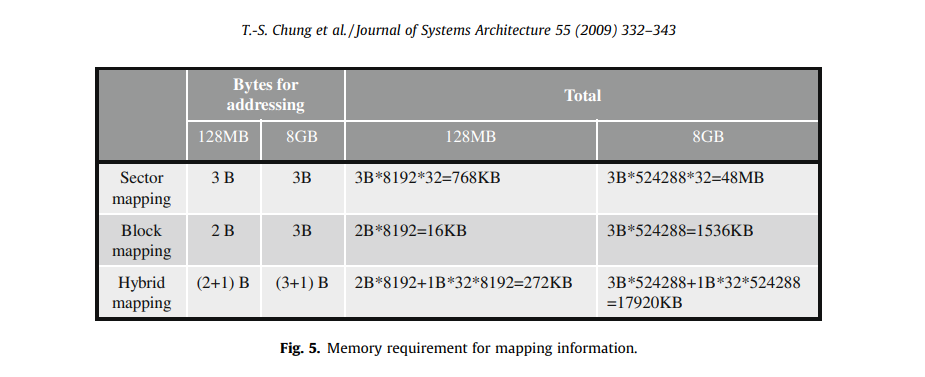
매핑 정보를 저장하기 위한 메모리(RAM) 요구 사항
매핑 정보는 영구 스토리지에 저장되어야 하며, 더 나은 성능을 위해 RAM으로 캐싱할 수 있음
(※ 플래시 메모리의 용량이 128MB(8192개 블록 포함)와 8GB(524288개 블록)라고 가정,
각 블록은 32개의 섹터로 구성)
섹터 매핑 - 128MB, 8GB 모두 섹터 번호를 나타내기 위해 3byte 필요
블록 매핑 - 128MB, 8GB 모두 섹터 번호를 나타내기 위해 2byte 필요
하이브리드 매핑 - 128MB는 블록매핑에 2byte, 섹터 매핑에 1byte 필요 (총 3byte)
8GB는 블록매핑에 3byte, 섹터 매핑에 1byte 필요 (총 4byte)
-> 블록매핑이 최소한의 RAM 메모리를 요구함
3.2 주소 매핑 정보 관리
FTL을 구현할 때, 매핑 정보를 저장하는 체계를 고려 해야함
절원을 켤 때 매핑 테이블을 재구성하려면, 전원이 꺼질 때 매핑 정보가 손실되지 않아야 하고, 그를 위해 플래시 메모리에 지속적으로 보관되어 있어야 함
-> 맵 블록 메소드(map block method), 블록별 메소드(per block method)
3.2.1 Map block method
매핑 정보를 맵 블록이라고 하는 플래시 메모리의 전용 블록에 저장함
블록 매핑의 경우 하나의 블록이 모든 패밍 정보를 저장할 수 있으나, 대부분 FTL 구현은 두 개 이상의 블록을 사용함
하나의 블록만 사용할 경우 맵블록의 지우기 작업이 매우 자주 발생함
-> 빈번한 삭제를 줄이기 위해 몇 개의 Map block을 사용함

매핑 정보(로컬 블록 번호와 물리 블록 번호의 짝)는 가장 최근에 사용되지 않은 맵 블록안 섹터에 기록
물리 블록 번호는 섹터 안에 논리 블록 번호 순서대로 저장된다.
한 블록에 물리 블록 번호를 모두 저장할 수 없는 경우 두 개 이상의 구역을 사용한다.
만약 파일시스템 쓰기 명령에 의해 매핑 정보가 변경된다면, 위 기록 작업이 실행된다.
기록 작업을 수행할 때 맵 블록 광간에 사용하지 않는 섹터가 없다면, 일부 맵 블록을 비우기 위해 지우기 작업이 실행해야 한다.
매핑 테이블은 빠른 매핑 검색을 위해 램에 캐시할 수 있음
이런 경우 매핑 테이블은 켜기 작업 중에, 플래시 메모리 안의 최신 맵블록의 최신 섹터를 읽어 재구성 해야 한다.
3.2.2. Per block method
매핑 정보는 플래시 메모리의 각 물리 블록에 저장

논리 블록 번호는 각각의 물리 블록의 첫 번째 페이지의 예비 영역 안에 저장 된다.
로컬 섹터 번호에서 물리 블록의 섹터에 대한 매핑을 유지 하기 위해, 논리 섹터 번호는 블록의 각 섹터에 기록함
전원이 꺼지고 매핑 테이블을 재구성할 때, 플레시 메모리의 예비 영역에 있는 논리 블록 번호와 논리 섹터 번호가 모두 사용
그림 7에서 논리 블록 번호3은 물리 블록 0에 매핑, 논리 블록 번호 2는 물리 블록 1에 매핑
3.3 RAM table
RAM의 크기는 전체 시스템 비용의 핵심 요소이기 때문에, FTL 설계에 매우 중요
-> RAM이 작으면 시스템 비용 절감 / RAM이 충분하면 성능이 향상
FTL은 자체 RAM 구조를 가지고 있으며, RAM 구조에 따라 분류가 가능함
RAM이 저장하는 정보
- 논리-물리 매핑 정보 : RAM의 주요 용도, RAM에 엑세스를 통해 데이터를 읽고 쓰기 위한 물리적 플래시 메모리 위치를 효율적으로 탐색
- 사용 가능한 메모리 공간 정보 : 한번 플래시 메모리의 사용 가능한 메모리 공간 정보를 RAM에 저장하면, FTL은 더이상 플래시 메모리에 엑세스 할 필요 없이 메모리 공간을 관리할 수 있음
- 분산 쓰기(Wear-leveling) 정보 : Wear-leveling 정보를 RAM에 저장 (ex. 플래시 메모리 블록의 지우기 수를 RAM에 저장)

위 시스템의 플래시 메모리 블록은 16개의 섹터로 구성
1:2 블록 매핑 방법 사용
PBN1, PBN2 : 첫 번째, 두 번째 물리적 블록 주소
논리 블록 00은 물리 블록 00과 10에 매핑되어 있음
논리 블록 00의 섹터 0번은 물리 블록 10의 섹터 0에 저장
예제 RAM 테이블에서,
Move flag - 한 블록의 일부 섹터가 다른 블록에 저장되어 있음
Used flag - 블록이 사용 중임
Old flag - 블록의 데이터가 유효하지 않음
Defect flag - 블록이 불량 블록임을 나타냄
- 참고 문헌 -
A survey of Flash Translation Layer
http://idke.ruc.edu.cn/people/dazhou/Papers/AsurveyFlash-JSA.pdf
'개인 공부 > Flash Memory' 카테고리의 다른 글
| A survey of Flash Translation Layer (2021-02-11) (0) | 2021.02.11 |
|---|---|
| A survey of Flash Translation Layer (2021-02-09) (0) | 2021.02.09 |
| A survey of Flash Translation Layer (2021-02-07) (0) | 2021.02.07 |
| Coding for SSD (2021-02-04) (0) | 2021.02.04 |
| Coding for SSD (2021-02-03) (0) | 2021.02.03 |